Note: Descriptions are shown in the official language in which they were submitted.
CA 02560159 2006-09-19
2
METHOD AND APPARATUS FOR CONCEPT-BASED VISUAL
PRESENTATION OF SEARCH RESULTS
This invention is in the field of search techniques used by search engines and
more
specifically methods and systems for displaying the results of searches.
BACKGROUND
The World Wide Web has given computer users on the Internet access to vast
amounts of
information in the form of billons of Web pages. Each of these pages can be
accessed
directly by a user typing the URL (universal resource locator) of a web page
into a web
browser on the user's computer, but often, a person is more likely to access a
website by
finding it with the use of a search engine. A search engine allows a user to
input a search
query made up of words or terms that a user thinks will = be used ' in the web
pages
containing the information he or she is looking for. The search engine will
attempt to
match web pages to the terms in the search query and will then return the
located web
pages to the user. '
The search results generated from a user's query typically consist of a
collection of
document surrogates, each of which contains summary information, attributes,
and other
meta-data about the matched documents. These document surrogates are often
presented
in a simple list-based format, displaying the title of the document, a snippet
containing
CA 02560159 2006-09-19
3
the query terms in context, and the uniform resource locator (the URL). A user
can then
select one of the returned entries to view the corresponding web page.
With the continued growth of web pages available on the Internet making the
task of
search engines more and more difficult, web search engines have greatly
increased the
size of their indexes and made significant advances in the algorithms used to
match a
user's query to these indexes. However, while it is clear that significant
effort has gone
into creating web search engines that can index billion of documents and
return the
search results in a fraction of a second, this has resulted in the creation of
the problem of
search queries returning numerous results.
While relevant documents might be present in the search results returned from
a search
engine, often the returned search results consist of tens or hundreds of
individual
documents making it hard for a user to determine which of the search results
may or may
not be relevant to the information the user is looking for.
While information retrieval techniques used by web search engines have
improved
substantially over the years, the search results are still typically
represented in a simple
list-based format. Although this list-based representation makes it easy to
evaluate a
single document, it does not support the users in the broader tasks of
manipulating the
search results, comparing documents, or finding a set of relevant documents.
Even
though this simple list-based representation provides the search results in a
clear and
effective manner for determining the relevance of individual document
surrogates, it
requires that each document surrogate be evaluated in nun, and to some degree,
in the
CA 02560159 2006-09-19
4
order provided. If hundreds of documents are returned it is inefficient if not
completely
impractical to have a user review hundreds of results to determine the most
relevant
documents located in the search. Requiring users to evaluate each document
surrogate
individually, often with only ten documents per page, leads to a common user
search trait
of evaluating only a few pages of search results before either re-formulating
their query
or giving up.
One solution that can be used to address these numerous search results is for
the user to
reformulate his or her search query to narrow the search with the result that
fewer
document are located matching the search query, however, in many cases there
may be
high quality relevant documents buried in the search results set that were
missed because
the users did not look at enough search result pages.
Another method that has also been used is to cluster the search results such
that
documents that are similar to one another are grouped together. In such a
system, a user
navigates the clusters in order to narrow down the search results and avoid
clusters of
irrelevant documents. Ideally, the user will select the relevant clusters and
view lists of
the returned documents in which a large portion are relevant to the
requirements of the
user.
One of the problems with these systems is that determining what the clusters
should be
centered around and determining an adequate description of the cluster. If the
information does not correctly describe the document contained in the cluster,
a user may
CA 02560159 2011-09-08
- Page 5 -
Either choose clusters that are not relevant or entirely miss clusters that
may contain
relevant documents.
SUMMARY OF THE INVENTION
It is an object of the present disclosure to provide a system and method that
overcomes
problems in the prior art.
In a first aspect of the present disclosure, a computer implemented method of
displaying
search results, the computer comprising at least one processor for executing
computer
readable instructions stored in a memory, the method comprising: receiving at
the
computer a search query containing at least one of search term to conduct a
search of a
plurality of computer readable documents; obtaining search results comprising
at least one
returned document based on the at least one search term of the search query;
determining
at least one concept related to the search query by matching the at least one
search term to
the at least one concept in a concept knowledge base; evaluating the
similarity between
the at least one returned document and the at least one concept to determine
an accordance
value indicating a similarity between the at least one returned document and
the at least
one concept; and displaying the at least one returned document with the
accordance value.
In a second aspect of the present disclosure, a data processing system for
displaying search
results comprising: at least one processor; a memory operatively coupled to
the at least
one processor; a display device operative to display data; and a program
module stored in
CA 02560159 2011-09-08
- Page 6 -
the memory and operative for providing instructions to the at least one
processor, the at
least one processor responsive to the instructions of the program module, the
program
module operative for: receiving a search query containing at least one search
term to
conduct a search of a plurality of computer readable documents; obtaining
search results
comprising at least one returned document based on the at least one search
term of the
search query; determining at least one concept related to the search query by
matching the
at least one search term to the at least one concept in a concept knowledge
base;
evaluating the similarity between a returned document and the at least one
concept to
determine an accordance value by determining a first accordance value by
evaluating the
similarity between the first returned document and the at least one concept
and a second
accordancevalue by evaluating the similarity between the second returned
document and
the at least one concept; and displaying the first returned document and
second returned
document sorted in an order based on the first accordance value and the second
accordance value.
CA 02560159 2011-09-08
- Page 7 -
DESCRIPTION OF THE DRAWINGS
CA 02560159 2006-09-19
8
While the invention is claimed in the concluding portions hereof, preferred
embodiments
are provided in the accompanying detailed description which may be best
understood in
conjunction with the accompanying diagrams where like parts in each of the
several
diagrams are labeled with like numbers, and where:
Fig. 1 is a schematic illustration of a data processing system suitable for
supporting the operation of methods in accordance with the present invention;
Fig. 2A is a schematic illustration of a network configuration suitable for
supporting the operation of methods in accordance with the present invention
wherein the data processing system is connected over a network to a plurality
of
servers operating as a search engine;
Fig. 2B is a schematic illustration of a network configuration suitable for
supporting the operation of methods in accordance with the present invention
wherein the data processing system is configured as a server and a remote
device
is used to access the data processing system;
Fig. 3 is an architectural schematic of a data structure for a concept
knowledge
base in accordance with an aspect of the present invention;
Fig. 4 illustrates a flowchart of a method of automatically creating a data
structure
containing a concept knowledge base in accordance with the present invention;
CA 02560159 2006-09-19
9
Fig. 5 is a schematic diagram of an overview of a software system in
accordance
with an aspect of the present invention;
Fig. 6 illustrates a flowchart of a method for generating a set of concepts
based on
the search terms in the search query in accordance with an aspect of a present
invention;
Fig. 7 is a typical document surrogate data object, which is commonly provided
as
a returned document by a search engine as one of a set of search results;
Fig. 8 is a flowchart of a method of determining accordance values for each
returned document in a set of search results;
Fig. 9 is an embodiment of a graphical interface displaying a number of
returned
documents with accordance indicators;
Fig. 10 is another embodiment of a graphical interface displaying a number of
returned documents with accordance indicators and sorted by accordance values;
and
CA 02560159 2006-09-19
Fig. 11 is an embodiment of a graphical interface displaying a number of
returned
documents with a plurality of accordance indicators for each displayed
returned
document.
5
DETAILED DESCRIPTION OF THE ILLUSTRATED EMBODIMENTS
DATA PROCESSING SYSTEM
10 Fig. 1 illustrates a data processing system 1 suitable for supporting the
operation of
methods in accordance with the present invention. The data processing system 1
could be
a personal computer, server, mobile computing device, cell phone, etc. The
data
processing system I typically comprises: at least one processing unit 3; a
memory storage
device 4; at least one input device 5; a display device 6 and a program module
8.
The processing unit 3 can be any processor that is typically known in the art
with the
capacity to run the program and is operatively, coupled to the memory storage
device 4
through a system bus. In some circumstances'the data processing system 1 may
contain
more than one processing unit 3.
The memory storage device 4 is operative to store data and can be any storage
device that
is known in the art, such as a local hard-disk, etc. and can include local
memory
employed during actual execution of the program code, bulk storage, and cache
memories
CA 02560159 2006-09-19
11
for providing temporary storage. Additionally, the memory storage device 4 can
be a
database that is external to the data processing system 1 but operatively
coupled to the
data processing system 1.
The input device 5 can be any suitable device suitable for inputting data into
the data
processing system 1, such as a keyboard, mouse or data port, such as a network
connection, and is operatively coupled to the processing unit 3 and allowing
the
processing unit 3 to receive information from the input device 5.
to The display device 6 is a CRT, LCD monitor, etc. operatively coupled to the
data
processing system 1 and operative to display information. The display device 6
could be
a stand-alone screen or if the data processing system f is a mobile device,
the display
device 6 could be integrated into a casing containing the processing unit 3
and the
memory storage device 4.
IS
The program module 8 is stored in the memory storage device 4 and operative to
provide
instructions to processing unit 3 and the processing unit 3 is responsive to
the instructions
from the program module 8.
20 Although other internal components of the data processing system 1 are not
illustrated, it
will be understood by those of ordinary skill in the art that only the
components of the
data processing system 1 necessary for an understanding of the present
invention are
CA 02560159 2006-09-19
12
illustrated and that many more components and interconnections between them
are well
known and can be used.
Fig. 2A illustrates a network configuration wherein the data processing system
1 is
connected over a network 55 to a plurality of servers 50 operating as a search
engine.
Fig. 2B illustrates a network configuration wherein the data processing system
1 is
configured as a server and a remote device 60, such as another computer, a
PDA, cell
phone or other mobile device connected to the Internet, is used to access the
data
processing system 1. The data processing system 1 runs the majority of the
software and
methods, in accordance with the present invention, and accesses a plurality of
servers 50
operating as a search engine to conduct a web search. By having the data
processing
system 1 configured as a server, the remote device 60 does not need to have
the capacity
necessary to contain all the necessary data structures and rim all the
methods.
Furthermore, the invention can take the form of a computer readable medium
having
recorded thereon statements and instructions for execution by a data
processing system 1.
For the. purposes of this description, a computer readable medium can be any
apparatus
that cats contain, store, communicate, propagate, or transport the program for
use by or in
connection with the instruction execution system, apparatus, or device. The
medium can
be an electronic, magnetic, optical, electromagnetic, infrared, or
semiconductor system
(or apparatus or device) or a propagation medium. Examples of a computer-
readable
medium include a semiconductor or solid state memory, magnetic tape, a
removable
computer diskette, a random access memory (RAM), a read-only memory (ROM), a
rigid
CA 02560159 2006-09-19
13
magnetic disk and an optical disk. Current examples of optical disks include
compact
disk - read only memory (CD-ROM), compact disk - read/write (CD-RJW) and DVD.
CONCEPT KNOWLEDGE BASE
Fig. 3 illustrates an architectural schematic of a data structure for a
concept knowledge
base 10, in accordance with an aspect of the present invention. The data
structure is
stored on a memory and is accessible by an application program being executed
by a data
processing system, such as the data processing system 1 illustrated in Fig. 1.
The data
structure contains information that is accessible by the application program.
The concept knowledge base 10 contains information relating to a field of
knowledge.
For example, the concept knowledge base 10 could contain information related
to the
field of science. The concept knowledge base 10 contains a number of concept
data
objects 12, a number of term data objects 14 and a number of edge data objects
16.
is
Each concept data object 12 contains a concept field 13 containing a concept
that is
related to a specific concept falling within the field of knowledge of the
concept
knowledge base 10. The concept field 13 typically contains a text string
identifying the
concept. For example, if the concept knowledge base 10 is for computer
science, there
may be concept data objects 12 with the concept field 13 containing the text
string of
"computer graphics", another concept data object 12 with the concept field 13
containing
the text string of "distributed computing", another concept data object 12
with the
concept field 13 containing the text string "artificial intelligence", etc.
CA 02560159 2006-09-19
14
Each term data object 14 contains a term field 15 containing a text string.
The text string
contains a word or phrase that describes a concept of one of the concept data
objects 12.
Each concept data object 12 is associated with one or more term data objects
14 and each
term data object 14 is associated with one ore more concept data objects 12.
The
association of a concept data object 12 and a term data object 14 is defined
by an edge
data object 16 which contains a weight field 18. A term data object 14 that is
associated
with a concept data object 12 contains a term in the term field 15 that
describes the
concept contained in the concept field 13 of the concept data object 12. The
relevancy of
the term in the term field 15 of the term data object 14 to the concept in the
concept field
13 of an associated concept data object 12 is represented by a weight in the
weight field
18 of the edge data object 16.
While it is possible to manually construct the data structure containing the
concept
knowledge base 10, Fig. 4 illustrates a flowchart of a method of automatically
creating a
data structure containing a concept knowledge base in accordance with the
present
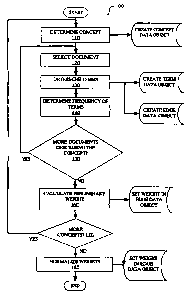
invention. '
Method 100 comprises the steps of. determining a concept 110; selecting a
document
describing the concept 120; determining terms in the document to be analyzed
130;
determining the frequency of the selected terms 140; checking if there are any
remaining
CA 02560159 2006-09-19
documents describing a concept 150; calculating a preliminary weight 160;
checking if
there are any more concepts 170; and normalizing all of the weights 180.
The method takes a number of documents and/or descriptions in computer
readable form
5 that describe a number of different concepts in a knowledge area and uses
the documents
to automatically generate a data structure of a concept knowledge base 10, as
shown in
Fig. 3.
The method 100 begins with step 110. A concept failing within the concept
knowledge
1o base is determined and a concept data object is created with information
identifying the
concept contained in the concept field.
Each concept will be described by one or more documents or descriptions in
computer
readable format. Once a concept has been determined at step 110, one or more
15 documents describing the concept are identified and at step 120 one of
these documents is
selected to be analyzed.
At step 130, the method 100 determines the terms'to be analyzed in the
document. For
each term to be analyzed, method 100 creates a term data object for each
selected term
with the term field containing the term, if a term data object containing the
term does not
already exist. An edge data object indicating the association of the term data
object and
the concept data object is also created and after the method 100 is completed
will contain
CA 02560159 2006-09-19
16
a weight indicating the relation of the term data object with the associated
concept data
object containing the concept described by the document being analyzed.
The terms that are analyzed can include all of the words used in the document
or only
specific words in the documents. For example, common words that are basically
non-
descriptive, such as "the", "a", "this", etc. may be excluded from the
selected terms that
are selected for analysis at step 130.
At step 140 the frequency of each of the selected terms in the selected
document is
determined. The occurrence of each selected term in the document is
determined. The
occurrence of a selected term t} in the document being analyzed can easily be
determined,
via text matching, and is defined by the function:
f(d,t ,t1)
Each of the terms appearing in the document are then averaged based on the
number of
occurrences of all of the terms in the document. For example, the averaging
could be
done using the following equation:
r (d, rJ= f (d,'t')
f 1f(dlk,t1 )
CA 02560159 2006-09-19
17
where d k is the document being analyzed for the set of terms t-k = tj,a ,
..., tmtk) with m
being the number of terms in document d;k. This equation simply divides the
frequency
or tally of a term being analyzed by the total number of terms being analyzed
in
document dk. By conducting this averaging, the eventual weight determined for
each
association between a term node and a concept node takes into account the
number of
occurrences of a term in the document and provides a potentially more relevant
indicator
of the relation between the term data object to the concept data object
because words or
terms that appear often relative to the total number of terms will be given
more weight.
This preliminary averaging is used to try to prevent a single large document
describing a
concept from providing term weights that overshadow the weights provided by a
number
of smaller documents.
Next, at step 150, the method 100 checks to see if there are any more
documents related
to the concept that have not been analyzed. If there are more documents to be
analyzed
is related to the concept, the method 100 returns to step 120, selects the
next unanalyzed
document and repeats steps 130, 140 and 150. As long as more documents related
to the
concept exist, step 150, causes the method 100 to analyze all of the
documents. When
there are no'more documents related to the concept to be analyzed, the method
100
continues on to step 160.
At step 160 the method 100 calculates a preliminary weight for each of the
terms used in
the documents related to a single concept. For each term an interim weight mjs
is
CA 02560159 2006-09-19
18
calculated taking into account the average term frequency of the documents
related to the
concept.
w_Ek=1f*(d ,tf)
WV n
Wherein there are 1 ... n documents,
This equation, in its entirety, is as follows:
n f(da,tf)
k=1
f(d
%*
n
This calculation is used to prevent concepts with a large numbers of documents
from
producing term weights ,that overshadow term weights from concepts with fewer
documents describing the concept.
At step 170, the method 100 checks to see if there are any more concepts left
to be
evaluated. If there are concepts remaining that have not been analyzed, the
method 100
returns to step 110 and the next concept is selected to be analyzed. The
method 100 then
repeats steps 120, 130, 140, 150 and 160 determining a preliminary weight for
each of the
terms appearing in the documents describing the selected document. The method
100
continues to analyze each concept repeating steps 110, 120, 130, 140, 150, 160
and 170
CA 02560159 2006-09-19
19
until all of the concepts have been analyzed, at which point, the method 100
continues on
to step 180.
At step 180 the method 100 determines a normalized weight for each of the
terms
associated with the concepts. The preliminary weight wy* previously determined
for
each association between a term tj and a concept is divided by the sum of all
of the
weights determined for the term ti connected to r concepts. This equation is
shown as
follows:
*
w w_.
=
r
k=1w,' (k)
Wherein the index ji'k) is given by fx), x = I...r, representing the r
concepts to which
term i is connected to in the concept knowledge base.
The normalization of the weights is used to prevent common terms that are
included in
many of the documents for many concepts from having higher weight values than
other
less common terms. These terms are often of little value in describing a
concept. By
using normalization, the weights of common terms are significantly reduced.
Without
this normalization step, common terms that are included in many documents for
many
different concepts would have a very high weight, even though these terms are
of little
value in describing the concept. With this normalization step, the weights of
these
common terms are significantly reduced.
CA 02560159 2006-09-19
Additionally, rather than using the terms exactly as they appear in the
documents or
descriptions, in a further aspect of the invention, the stems of the roots of
the terms are
used to construct the knowledge base allowing terms to be matched based on
their stems
or roots rather than being based on exact text matches.
5
Additionally, in some circumstances it may not be necessary to analyze every
term in a
document. In a further aspect, the method 100 will focus on only specific
terms in a
document that are highlighted in a particular way, i.e. in an abstract
Alternatively, there
could be a list of terms that are not analyzed, such as common terms that are
not
10 descriptive of a concept, for example terms such as the, and, etc. may be
excluded from
being selected.
At the conclusion of the method 100 a concept knowledge base as illustrated in
Fig. 3
will have been automatically constructed by the method 100.
OVERVIEW OF SYSTEM
Fig. 5 illustrates a software system in accordance with the present invention.
The
software system 200 contains: a search query module`210; a concept generator
module
220; a concept knowledge database 230; a search module 240; a search engine
module
250; a concept accordance module 260; and a visualization interface module
270.
A search query is input to the system 200 at the search query module 210. The
search
query contains one or more search terms and usually at least two or three
search terms.
CA 02560159 2006-09-19
21
From the search query module 210 this search query containing one or more
search terms
is passed to the concept generator module 220, which uses the concept
knowledge
database 230 to select a set of concepts and generate a concept vector for
each selected
concept.
The search terms and the concept vectors are passed from the concept generator
module
220 to the search module 240 where the search module 240 requests a search
from the
search engine 250 using the search query and receives search results.
Typically, the
results returned by the search engine module 250 are a list of returned
documents, where
each returned document is typically a document surrogate that describes the
actual
documents located by the search engine module 250.
As the search results are received from the search engine module 250, the
search engine
module 250 passes the returned document to the concept accordance module 260
where a
document vector is determined for each of the returned document and an
accordance
value indicating the similarity of the returned document to each of the
concepts in the
concept set is formulated. A fuzzy membership score is typically determined
for the
returned document relative to each of the concepts in the concept set and is
used for the
accordance value.
The search module 240 can wait until all the search results are returned from
the search
engine module 250 before passing the search results all together to the
concept
accordance module 260, however, in one embodiment, the search module 240
passes
CA 02560159 2006-09-19
22
each returned document of the search results to the concept accordance module
260 as the
search module 250 receives the returned document to decrease the time required
by the
system 200 to display the search results.
Finally, the concept set and the search results (comprising a plurality of
returned
document), with each returned document having an accordance value indicating
the
similarity of the returned document to each of the concepts in the concept
set, are passed
to the visualization interface module 270 wherein the visualization interface
module 270
displays the search results to a user.
The software system 200 can be implemented wholly on a data processing system,
such
as the data processing system I shown in Fig. 2A, with only the search engine
module
250 resident on a server 50 connected to the data processing system I over the
network
55_ Alternatively, various components of the software system 100, such as the
search
query module. 210 could be resident on a mobile device 60 operably connected
to a data'
processing system 1 which contains other components of the software system
200, (such
as the concept generator 220, search module 240, etc.) as shown in Fig. 2B.
OBTAINING THE CONCEPTS
The software system 200 begins with an initial search query being input to the
search
query module 210 which passes the search query to the concept generator module
220.
The concept generator module 220 accesses the concept knowledge database 230
and
CA 02560159 2006-09-19
23
uses the information in the concept knowledge database 230 to generate a
concept set and
a respective set of concept vectors using the search query.
Fig. 6 illustrates a flowchart of a method 400 for generating a set of
concepts based on
the search terms in the search query. Method 400 is implemented by the concept
generator module 220 in Fig. 4, using the concept knowledge database 230. When
a
search query is passed to the concept generator module 220, the method 400
uses the
concept knowledge database 230 to generate a list of concepts using
relationships
between the search terms and concepts.
Method 400 comprises the steps of: matching terms in the search query to term
data
objects in the concept knowledge base to obtain a first term set 410;
obtaining a concept
set of concept data objects associated with the first term set 420; obtaining
a second term
set of term data objects associated with the concepts objects in the concept
set 430; and
formulating a set of concept vectors 440.
The method 400 begins with step 410 and matching the terms in the search query
to term
data objects in the concept knowledge database 230. The concept knowledge
database'
230 is accessed and the terms making up the search query are matched with any
term data
objects that have a term in the term field matching the term in the search
query. A first
term set containing these selected term data objects is obtained. After step
410 is
completed, all of the term data objects in the concept knowledge database 230
that have a
CA 02560159 2006-09-19
24
term in the term field that corresponds to one of the terms in the search
query are
identified and these term data objects have been added to a first term set.
At step 420, the first term set is used to obtain a concept set containing
concept data
objects from the concept knowledge database 230 associated with one or more
term data
objects in the first term set. The term data objects making up the first term
set are used to
obtain a number of concept data objects from the concept knowledge database
230.
Concept data objects associated with one or more term data objects in the
first term set
are selected to form the concept set.
to
Concept data objects that are not strongly associated with term data objects
in the first
term set can be excluded from the concept set using a first weight threshold
and a term
ratio threshold. The first weight threshold is used to exclude concept data
objects that are
not strongly associated with one of the term data objects in the first term
set by
comparing the weight assigned to an. association between a concept data object
and a
term data object and excluding the concept data object from the concept set if
the weight
determined for the association is less than the first weight threshold. By
using this first
weight threshold, the concept set is limited to only the more relevant
concepts.
Additionally, a term ratio threshold is used to further exclude concept data
objects from
the concept set. If a concept data object is associated with one of the term
data objects in
the first term set with a weight greater than the first weight threshold, the
concept data
object is evaluated to determine the ratio of all of the term data objects in
the first term
set to which the concept data object is associated with a weight greater than
the first
CA 02560159 2006-09-19
weight threshold. If this ratio is less than the term ratio threshold, the
concept data object
is excluded from the concept set.
Through experiments, the first weight threshold, term ratio threshold and
second weight
5 threshold can be determined. For example, some initial studies found that a
first weight
threshold of 0.05, a term ratio threshold of 0.26 and a second weight
threshold of 0.10
provided satisfactory results.
At step 430 a second term set is obtained for each of the concept data objects
in the
to concept set. Each of the concept data objects in the concept set are
evaluated to
determine term data objects, in the concept knowledge database 230, associated
with each
of these concept data objects. Term data objects associated with the concept
data objects
selected for the concept set are added to the second term set. A second weight
threshold
may be used to exclude term data objects from the second term set if they are
associated
15 with concept data objects in the concept sets by a weight that is less than
the second
weight threshold.
At step 440. the concept set is used to formulate d set of concept vectors.
For each
concept represented by a concept data object in the concept set, a concept
vector is
20 created using the first term set and second term set obtained for the
concept data object at
step 430. Each term data object in the first term set and second term set for
a concept
data object is defined as a dimension of the concept vector and the weight of
the
CA 02560159 2006-09-19
26
association between the term data object and the concept data object is used
to set the
magnitude of the concept vector in that assigned dimension.
At this point, the method 400 ends and a set of concepts and their
corresponding concept
vectors C = I ci, c2, ..., cm }have been determined.
Referring again to Fig. 5, from the concept accordance module 260, the concept
set and
the respective concept vectors are passed to the search module 240 to request
a search
using the search query.
SEARCH MODULE
When the search module 240 receives the search query, the concept set and the
set of
concept vectors, the search module 240 requests the search engine module 250
to conduct
a search using the search query. The search module 240 is typically resident
on the data
proeessing'system 1 and the search engine module 250 is typically a web search
engine,
such as the web search engine running on servers 50 in Figs. 2A and 2B, with
the search
being conducted on a number of computer readable documents, such as searching
for web
pages on the World Wide Web. However, the search engine module 240 could be
used in
any computerized document storage system capable of searching a large number
of
computer readable documents.
The search engine module 240, could return the results of the search in the
form of a list
of complete documents located in the search, however, due to the likelihood
that a
CA 02560159 2006-09-19
27
relatively large number of documents can be located with the search and to
save overhead
on the data processing system, the search results are typically returned in
the form of list
of document surrogates, with a document surrogate returned for each document
located in
the search.
Fig. 7 illustrates a typical document surrogate data object 160 which is
commonly
provided as a returned document by a search engine as one of a set of search
results.
Rather than a search engine returning each complete document that is located
in a search,
search engines typically provide a set of document surrogates 160 in place of
supplying
to the completed documents. Document surrogates 160 are the primary data
objects in the
list-based representation used by search engines. Each document surrogate 160
provides
information describing the corresponding complete document which commonly
consists
of. a title 162; a URL 164; a summary 166; and any other additional other
assorted
information. The title 162 provides the title of the corresponding complete
document
described . by the document surrogate 160, the URL 164 provides the address of
the
complete document and the summary 166 contains a short description or snippet
of the
complete document and usually provides the query terms of the search term in
context.
Referring again to Fig. 5, the search results obtained by the search module
240 are passed
to the concept accordance module 260 where accordance values for each return
document
indicating the degree of similarity between the returned document and the
concepts in the
concept set are formulated.
CA 02560159 2006-09-19
28
CONCEPT ACCORDANCE
Fig. 8 illustrates a method 500 of determining accordance values for each
returned
document of the search results. Each returned document has an accordance value
determined for each concept in the concept set and indicating the degree of
similarity
between the returned document and the concept. The accordance value is
typically based
on a fuzzy membership score with each concept in the concept set treated as a
centroid to
determine the clustering of the returned documents around the concepts. A
returned
document might have a higher fuzzy membership score in relation to one concept
as
compared to another concept, indicating that the first concept has a higher
degree of
1o similarity to the returned document than the second concept.
Method 500 comprises the steps of: selecting a first returned document 510;
analyzing the
returned document 520; generating a document vector 530 for the selected
returned
document; selecting a first concept 540; determining an accordance value for
the selected
returned document in relation to a selected concept 550; checking if more
concepts
remain in the concept set to be analyzed 560 in relation to the selected
returned document
and selecting the next concept 570, if more concepts remain in the concept
set; once the
selected returned document has been analyzed in relation to all the concepts
in the
concept set, checking if more returned documents are present 580 and selecting
the next
returned document 590, if there are more returned documents; and ending when
all the
returned documents have an accordance indicator determined for each of the
concepts in
the concept set.
CA 02560159 2006-09-19
29
The method 500 begins with the selection of a first returned document at step
510. As
the search results are returned, the method 500 selects one of the returned
documents
returned as the search results.
Next at step 520, the returned document is analyzed to determine a frequency
of each
unique word or term in the returned document. If the returned document is the
entire
document, the occurrence of each unique term in the entire document is
determined. If
the returned document is a document surrogate the occurrence of each unique
term can be
determined based on the summary of the complete document and optionally in the
title.
In some cases it may be preferable to use the roots of the words rather than
the words
themselves, such as using Porter's stemming algorithm, so words with various
prefixes
and suffixes are not counted as separate terms. Each unique term in a returned
document
will be based on the root or stem of the term so that the frequencies
determined are not
reduced by the use of terms that use different suffixes, prefixes, etc.
Matching based on
the stems or roots of the search terms can be more effective than exact word
matches,
since it takes into account different variations of the same root word.
The frequencies determined for the unique terms in the selected returned
document are
then used to generate a document vector at step 530. The document vector
represents the
frequency of unique terms in the returned document in a multi-dimensional
vector form.
Each unique term is used to define a dimension of the document vector and the
CA 02560159 2006-09-19
magnitude of the document vector in that dimension is then set as the
frequency of the
term in the returned document.
A fast one of the concepts in the concept set is selected at step 540 and an
accordance
s value indicating the degree of similarity between the returned document and
the selected
concept is determined at step 550. The accordance value is assigned by
determining a
fuzzy membership score of the returned document relative to the selected
concept. Given
the concept set, the corresponding concept vector set, C = (cl, c2, ..., cm),
and the
document vector d;, determined for the returned document determined at step
530, the
10 fuzzy membership score, uij, of the returned document can be determined
with respect to
a concept cj by the following equation:
u1,J sim(di c!)
)2
sim(di xk)
k=1
15 Where sim(di cj) or the similarity between a document vector and a concept
vector is
given by the Euclidean distance metric:
sim(x,,x1)=(L.rt l(xi.k -xj.k)Z)t/2
where x; is the document vector and xj is the concept vector.
CA 02560159 2006-09-19
31
Although a specific clustering algorithm is provided a person skilled in the
an will
appreciate that other clustering algorithms could also be used.
The method 500 then checks, at step 560, to see if more concepts remain in the
concept
set and if more concepts remain, the next concept in the concept set is
selected at step 570
and an accordance value consisting of a fuzzy membership score for the newly
selected
concept is determined at step 550. The method 500 will continue to repeat
steps 550, 560
and 570 until all the concepts in the concept set of been selected and an
accordance value
determined for each of the returned document has been established for each of
the
1o concepts in the concept set.
At step 580, if more returned documents are remaining, the next returned
document is
selected at step 590 and steps 520, 530, 540, 550, 560, 570, 580 and 590 are
repeated
until all of the repeated documents have been returned.
15.
In this manner, the method 500 determines a document vector for each of the
returned
documents and uses the document vector to determine a fuzzy membership score
for the
returned document and each concept in the concept set, which' is used then to
assign an
accordance value indicating the similarity between the returned document and
each of the
20 concepts in the concept set.
In one embodiment of the present invention, each returned document in a set of
search
results is evaluated as the returned document is returned from the search
engine module
CA 02560159 2006-09-19
32
250 to decrease the amount of time the system requires before displaying the
search
results to a user.
At the end of the method 500 each of the returned documents will have an
accordance
value determined in relation to each of the concepts in the concept set.
From the concept accordance module 260, the search results comprising the
plurality of
returned documents and the formulated accordance values are passed to the
visualization
interface module 270.
VIZUALIZATION INTERFACE
The visualization interface module 270 displays the search results in a manner
that allows
a user to quickly determine the degree of similarity between one or more
concepts in a
concept set and a returned document. Additionally, the search results are
displayed in
such a way that *a user can determine whether a first returned document is
more or less
similar to one or more selected concepts than a second returned document.
Referring to
Fig. 5, the search results in the form of a list of returned documents (with
the accordance
values determined for each returned document) and the concept set are passed,
from the
concept accordance module 260, to the visualization interface module 270 where
the
search results are displayed to a user.
Fig. 9 illustrates a screen shot of an embodiment of a graphical interface 600
that may be
generated by the visual interface module 270 shown in Fig. 5, for displaying
the search
CA 02560159 2006-09-19
33
results. A compressed level of detail provides the user with a large overview
of a large
number of the search results and a more detailed level of view provides more
detailed
information about a smaller number of the search results.
A first portion 610 of the list of returned documents is shown in the
graphical interface
600. Typically, each returned document shown in the first portion 610
comprises an
accordance indicator 614 and a title 636. The title 636 provides readable text
showing
the title of the returned document and is typically a hyperlink to the actual
located
document, such as the webpage located in a web search or the document in an
information retrieval system.
Each returned document in the first portion 610 can be displayed with the
summary of the
returned document. Alternatively, each returned document in the first portion
610 can
display the summary of the returned document only when a user moves a cursor
over the
returned document. in the first portion 610. When the user moves a cursor over
the
returned document in the first portion 610, a popup field (tool tip) can
appear containing
the summary of the returned document.
Each returned document in the first portion 610 is displayed with an
accordance indicator
614. The accordance indicator 614 is based on the accordance values formulated
for the
returned documents and indicates the similarity between a returned document
and one or
more of the concepts in the concept set generated using the search terms in
the search
wry.
CA 02560159 2006-09-19
34
The accordance values consisting of the fuzzy membership scores determined for
each
returned document in relation to the concepts in the concept set, using method
500,
illustrated in Fig. 8, are used to formulate the accordance indicators 614.
Each concept
685 in the set of concepts is displayed in a viewing pane 680. A user can
select one or
more of the concepts 685. If a user selects only a single concept 685, the
accordance
indicator 614 shows the accordance value of each returned document in relation
to the
selected concept. However, if the user selects more than one of the concepts
685 in the
concept set, the accordance indicator 614 is the result of the addition of the
accordance
values of each returned document in relation to all of the selected concepts.
Typically, a color shade is assigned to each accordance indictor 614 based on
the
accordance values of the selected concepts for each returned document.
Typically,
returned documents with higher accordance values for the selected concepts
(more
similarity between a selected concept and a returned document) are assigned a
color
shade that is more intense or deeper. For example, an accordance indicator 614
indicating a relatively low accordance may have a very pale yellow color,
while an
accordance indicator 614 indicating a higher accordance may be a color shade
of a much
darker red.
A second portion 630 of the list of returned documents is shown in the
graphical interface
600. The first portion 610 is a subset of the returned documents shown in the
second
portion 630. The second portion 630 displays each returned document in a much
smaller
CA 02560159 2006-09-19
format so that the second portion 630 displays more of the returned documents
than the
first portion 610 however, the first portion 610 provides more information
regarding each
displayed returned documents than the returned documents displayed in the
second
portion 630.
5
Each of the returned documents in the second portion 630 is displayed in a
format which
provides a compressed or small view of the returned document. Each returned
document
shown in the second portion 630 is displayed with an accordance indicator 614,
and,
typically, a title representation 616.
The title representation 616 represents the title of the returned document;
however, the
title representation 616 does not necessarily have to provide the title in a
readable format.
Returned documents displayed in the second portion 630 may be displayed so
small that a
solid line is used to provide the title representation 616 and the title
representation 616
merely indicates the approximate length of the title of the returned document
in relation
to the length of the titles of the other returned documents.
By displaying a more detailed first portion 610 of the list of returned
documents and a
less detailed second portion 630 of the list of returned documents; where the
second
portion 630 contains many more returned documents than the first portion 610
the
interface 600 provides two levels of detail to a user about returned documents
provided in
the list returned as the search results.
CA 02560159 2006-09-19
36
Each of the returned documents displayed in the second portion 630 corresponds
to a
returned document displayed in the first portion 610, such that all of the
returned
documents in the first portion 610 are contained in the second portion 630,
with the
returned documents in the first portion 610 occurring in the same order that
they occur in
the second portion 630. The second portion 630 represents a subset of list of
returned
documents making up the search results from the search engine and the first
portion 610
represents a subset of the returned documents show in the second portion 630.
The first
format allows a user to see a large number of the returned documents in a
compressed
view in the second portion 630 and then also see some of these returned shown
in the
to second portion 630 in a larger, more detailed view in the first portion
610.
The accordance indicators 614 displayed with the returned documents in the
first portion
610 indicates the same accordance values as the accordance indicators 614
associated
with the same returned document in the second portion 630.
15.
The second portion 630 displays a much greater portion of the list of returned
documents
than the first portion 610. In some cases, more than one. hundred (100)
returned
documents may be displayed in the second portion 630. Chi the other hand the
first
portion 610 displays a relatively smaller number of the returned documents
because the
20 returned documents displayed in the first portion 610 provides more details
and therefore
the returned documents must be shown in a large enough size that a user can
read the
titles 636 of the returned documents shown in the first portion 610. For
example, while
CA 02560159 2006-09-19
37
the second portion 630 may display one hundred (100) returned documents in the
first
format the first portion 610 may display fewer than twenty five (25) returned
documents.
While each of the accordance indicators 614 could be an assigned number such
as a
percentage, the use of a color shade as the accordance indicators 614 (or as
part of the
accordance indicators 614) allows the information to be conveyed to the user
even though
the returned document in the second portion 630 may be displayed too small for
a user to
either easily read or even be able to read text. Using a color shade for the
accordance
indicators 614, the accordance indicators 614 do not have to be very large in
order to
o convey the necessary information to a user; just large enough to convey to a
user a shade
of color. While numbers, text or geometric shapes cannot be illustrated using
a single
pixel; a color shade can be. In some cases, the accordance indicator 614 may
be made as
small as a single pixel of a display screen.
An indicator frame 650 is positioned over the returned documents in the second
portion
630 that are also shown in the first portion 610. The indicator frame 650
indicates the
return documents shown in the second portion 630 that are also shown in the
first
portion 610.
When a user makes a selection that changes the returned documents shown in the
first
portion 610, such as by using a scroll bar 660 to scroll to a new set of
returned documents
displayed in the first portion 610, the second portion 630 is updated to
indicate the same
CA 02560159 2006-09-19
38
returned documents shown in the first portion 610 in the second portion 630,
by moving
the indicator frame 650 along the second portion 630.
In this manner, a user can quickly look over the accordance indicators 614 for
each
returned document shown in the first portion 610 to determine which returned
documents
correlate to the desired concepts. Additionally, using the second portion 630,
a user can
quickly look over the accordance indicators 614 for each returned document in
the second
portion 630 and quickly determine which returned documents shown in the second
format
630 correlate to the desired concepts closer then the other returned documents
without
to requiring the user to perform any in-depth analysis of each returned
document. By
simply scanning over the accordance indicators 614 a user can quickly and
easily visually
locate the accordance indicators 614 that indicate a returned document that
has a high
correlation with a concept by the various shades of color shown in the
accordance
indicators 614.
A user can also visually analyze the returned documents shown in the first
portion 610,
checking for returned documents that contain accordance indicators 614
indicating the,
similarity of a returned document to one or more of the concepts. Once a user
identifies a
returned document or a grouping of returned documents in the first portion 610
that the
user wishes to examine in more detail, the user can then move the indicator
frame 660 so
that the selected returned documents or grouping of returned documents in the
second
portion 630 are displayed in the second format in the first portion 610. A
user can then
CA 02560159 2006-09-19
39
examine the titles 636 of the represented documents and click on a desired
returned
document title 636 to go to the document.
Fig. 10 illustrates a screen shot of a further embodiment of a graphical
interface 700 that
may be generated by the visual interface module 470 shown in Fig. 5, for
displaying the
search results wherein the accordance values of the returned documents in
relation to the
selected concept or concepts in the concept set are used to sort the returned
documents in
the first portion 610 and second portion 630. The returned documents are
sorted based on
the accordance values for the returned documents in relation to a selected
concept.
Returned documents that have a higher degree of similarity to a selected
concept (shown
with the accordance indicators 614) appear higher in the list than other
returned
documents that are less similar to the selected concept or concepts.
Fig. 11 illustrates a screen shot of a further embodiment of a graphical
interface 800 that
may be generated by the visual interface module 470 shown in Fig. 5, for
displaying the
search results. Graphical interface 800 is similar to graphical interface 600
(illustrated in
Fig. 9) in that a first portion 610 of a list of returned documents is
displayed with each
returned document displaying the title 636 and any other information. However,
instead
of displaying a single accordance indicator 614 with each returned document
wherein
when more than one concept from the concept set is selected the single
accordance
indicator 614 is made up of the sums of the accordance values of the selected
concepts,
graphical interface 800 provides a separate accordance indicator 814 for each
selected
concept. Each accordance indicator 814 displays a single accordance value
indicating the
CA 02560159 2012-05-01
similarity between a returned document and a specific concept in the concept
set. By
simply viewing the accordance indicators 813 a user can see how similar each
of the
displayed returned documents are to a specific concept. In this manner a user
can
compare: the similarity of a returned document to two or more of the concepts
in a
5 concept set.
A user can sort the list of the returned documents displayed in the graphical
interface 800
based on one concept over the one or more others by selecting one of the
concepts to sort
the list by. In one embodvnent, a user selects the concept the user desires
the list to be
sorted by. The list of returned documents is then resorted to place a
precedent on the
10 selected concept and the first portion 610 of returned documents and the
second portion
630 of the returned documents are updated to reflect the newly sorted list.
A user can also conduct a nested sort by selecting a second concept. The list
of returned
documents is then resorted to place a primary weight on returned documents
with high
accordance values with the first selected concept and then a secondary weight
on returned
15 documents with high accordance values with relation to the second selected
concept. The
first portion 60 of returned documents of and the second portion 60 of the
returned
documents are updated to reflect the newly sorted list.
The scope of the claims should not be limited by the preferred embodiments set
forth in
CA 02560159 2012-05-01
41
the examples, but should be given the broadest interpretation consistent with
the
description as a whole.